Docker SSHFS plugin external storage as Docker Volume
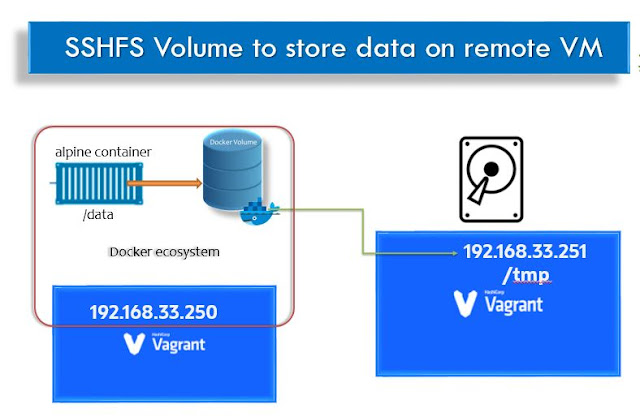
Namaste, In this exciting Docker storage volume story, this experiment is going to use two Vagrant VirtualBox. You can also use any two Cloud instances (may be GCP, AWS, Azure etc.,). Where DockerHost is going to run the docker containers and DockerClient box is going to run the SSH daemon. Docker Volume with External Storage using SSHFS Docker allows us to use external storage with constraints. These constraints will be imposed on cloud platforms as well. The external or Remote volume sharing is possible using NFS. How to install SSHFS volume? Step-by-step procedure for using external storage as given below : Install docker plugin for SSHFS with all permission is recommended: docker plugin install \ --grant-all-permissions vieux/sshfs Create a Docker Volume docker volume create -d vieux/sshfs \ -o sshcmd=vagrant@192.168.33.251:/tmp \ -o password=vagrant -o allow_other sshvolume3 Mount the shared folder on the remote host: mkdir /opt/remote-volume # In rea...



