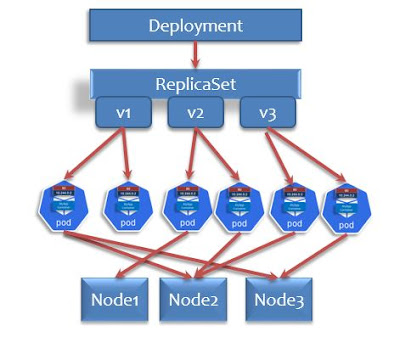
Kafka Message system on Kubernetes

Setting up the Kubernetes namespace for kafka apiVersion: v1 kind: Namespace metadata: name: "kafka" labels: name: "kafka" k apply -f kafka-ns.yml Now let's create the ZooKeeper container inside the kafka namespace apiVersion: v1 kind: Service metadata: labels: app: zookeeper-service name: zookeeper-service namespace: kafka spec: type: NodePort ports: - name: zookeeper-port port: 2181 nodePort: 30181 targetPort: 2181 selector: app: zookeeper --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: zookeeper name: zookeeper namespace: kafka spec: replicas: 1 selector: matchLabels: app: zookeeper template: metadata: labels: app: zookeeper spec: containers: - image: wurstmeister/zookeeper imagePullPolicy: IfNotPresent name: zookeeper ports: - containerPort: 2181 image1 - kube-kafka1 From th...