Apache Cassandra Performance Optimization
Hey Guys!! I'm back with a new learning this week, I worked and experimented on Apache Cassandra Distributed database. It's special feature is it's quering capability with NoSQL - Not only SQL.
Let's jump to our last set blog post where we have learnt about the Cassandra installation on a VM. Hope you are ready with Cassandra DB node.
Create an inefficient table within company_db keyspace:


Use Case: An IoT platform collects data from thousands of sensors distributed across a smart city. Each sensor sends data continuously, leading to a high volume of writes.
Advantage: STCS is ideal for this write-heavy workload because it efficiently handles large volumes of data by merging smaller SSTables into larger ones, reducing write amplification and managing disk space effectively.
Advantage: LCS is suitable for read-heavy workloads. It organizes SSTables into levels, ensuring that queries read from a small number of SSTables, resulting in lower read latency and consistent performance.

Advantage: UCS adapts to the changing workload by balancing the trade-offs of STCS and LCS. It provides efficient compaction for both read-heavy and write-heavy periods, ensuring consistent performance.
Let's jump to our last set blog post where we have learnt about the Cassandra installation on a VM. Hope you are ready with Cassandra DB node.
1: Optimizing Data Modeling
Objective: Understand partitioning and primary key design to optimize performance.Create an inefficient table within company_db keyspace:
CREATE KEYSPACE company_db
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE company_db;
CREATE TABLE company_db.employees_bad (
id UUID PRIMARY KEY,
name TEXT,
department TEXT,
age INT,
city TEXT
);
Now let's Insert some sample records into the table and try to query it.
INSERT INTO employees_bad (id, name, department, age, city) VALUES (uuid(), 'Reemi', 'Engineering', 30, 'New York'); INSERT INTO employees_bad (id, name, department, age, city) VALUES (uuid(), 'Ausula Santhosh', 'Marketing', 40, 'San Francisco'); INSERT INTO employees_bad (id, name, department, age, city) VALUES (uuid(), 'Telluri Raja', 'Marketing', 40, 'San Francisco'); INSERT INTO employees_bad (id, name, department, age, city) VALUES (uuid(), 'Abdul Pathan', 'Marketing', 40, 'San Francisco');Run the following queries and observe the issue SELECT * FROM employees_bad; SELECT * FROM employees_bad WHERE department = 'Engineering';
Resolve Data model performances
CREATE TABLE company_db.emp ( id UUID, name TEXT, department TEXT, age INT, city TEXT, PRIMARY KEY(department,id) );Rerun the Insert sample records
INSERT INTO emp (id, name, department, age, city) VALUES (uuid(), 'Reemi', 'Engineering', 30, 'New York'); INSERT INTO emp (id, name, department, age, city) VALUES (uuid(), 'Ausula Santhosh', 'Marketing', 40, 'San Francisco'); INSERT INTO emp (id, name, department, age, city) VALUES (uuid(), 'Telluri Raja', 'Marketing', 40, 'San Francisco'); INSERT INTO emp (id, name, department, age, city) VALUES (uuid(), 'Abdul Pathan', 'Marketing', 40, 'San Francisco');Run queries and observe performance
SELECT * FROM emp; SELECT * FROM emp WHERE department = 'Engineering';

2: Using Secondary Indexes Efficiently
Objective: Learn when to use secondary indexes and when to avoid them. Create a table without a proper partition key:CREATE TABLE company_db.products ( id UUID PRIMARY KEY, name TEXT, category TEXT, price DECIMAL ); INSERT INTO products (id, name, category, price) VALUES (uuid(), 'Laptop', 'Electronics', 120000.00); INSERT INTO products (id, name, category, price) VALUES (uuid(), 'Wireless Mouse', 'Electronics', 200.00); INSERT INTO products (id, name, category, price) VALUES (uuid(), 'Chair', 'Furniture', 150.00); INSERT INTO products (id, name, category, price) VALUES (uuid(), 'ErgoChair', 'Furniture', 1500.00); INSERT INTO products (id, name, category, price) VALUES (uuid(), 'ErgoStandSitTable', 'Furniture', 24050.00); SELECT * FROM products ; SELECT * FROM products WHERE category = 'Electronics';Create an index on category so that partition key forms with id and category fields after this optimization you are good to go, now rerun the query:
CREATE INDEX category_index ON products (category); SELECT * FROM products WHERE category = 'Electronics';

3: Compaction Strategies
Objective: Understand how different compaction strategies affect performance. We have 4 different options we have let's explore on each of these options in detail here. You can use `DESC TABLE emp`, This way we can check the current compaction strategy:
1. SizeTieredCompactionStrategy (STCS)
Scenario: An IoT application with a high volume of incoming sensor data.Use Case: An IoT platform collects data from thousands of sensors distributed across a smart city. Each sensor sends data continuously, leading to a high volume of writes.
Advantage: STCS is ideal for this write-heavy workload because it efficiently handles large volumes of data by merging smaller SSTables into larger ones, reducing write amplification and managing disk space effectively.
CREATE KEYSPACE iot
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
use iot;
CREATE TABLE iot.sensor_data (
sensor_id int,
timestamp timestamp,
data blob,
PRIMARY KEY (sensor_id, timestamp)
) WITH compaction = {
'class': 'SizeTieredCompactionStrategy',
'min_threshold': 4,
'max_threshold': 32
};
DESC TABLE iot.sensor_data

2. LeveledCompactionStrategy (LCS)
Scenario: A social media application with a focus on fast reads. Use Case: A social media platform requires fast access to user profiles and posts. Users frequently query the latest posts, likes, and comments.Advantage: LCS is suitable for read-heavy workloads. It organizes SSTables into levels, ensuring that queries read from a small number of SSTables, resulting in lower read latency and consistent performance.
CREATE KEYSPACE socialmedia
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE socialmedia;
CREATE TABLE socialmedia.user_posts (
user_id int,
post_id int,
content text,
PRIMARY KEY (user_id, post_id)
) WITH compaction = {
'class': 'LeveledCompactionStrategy',
'sstable_size_in_mb': 160
};
DESC TABLE socialmedia.user_posts

3. TimeWindowCompactionStrategy (TWCS)
Scenario: A time-series database for monitoring server performance. Use Case: A company uses Cassandra to store and analyze server performance metrics such as CPU usage, memory usage, and network traffic. These metrics are collected at regular intervals and are time-based. Advantage: TWCS groups data into time windows, making it easier to expire old data and reduce compaction overhead. It is optimized for time-series data, ensuring efficient data organization and faster queries for recent data.
CREATE KEYSPACE monitoring
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE monitoring;
CREATE TABLE monitoring.server_metrics (
server_id int,
metric timestamp,
cpu_usage double,
memory_usage double,
network_traffic double,
PRIMARY KEY (server_id, metric)
) WITH compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_unit': 'HOURS',
'compaction_window_size': 1
};
DESC TABLE monitoring.server_metrics

4. UnifiedCompactionStrategy (UCS)
Scenario: An e-commerce platform with mixed read and write workloads. Use Case: An e-commerce website handles a mix of reads and writes, including product catalog updates, user reviews, and order processing. The workload varies throughout the day, with peak periods during sales events.Advantage: UCS adapts to the changing workload by balancing the trade-offs of STCS and LCS. It provides efficient compaction for both read-heavy and write-heavy periods, ensuring consistent performance.
CREATE KEYSPACE ecommerce
WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1};
USE ecommerce;
CREATE TABLE ecommerce.orders (
order_id int,
user_id int,
product_id int,
order_date timestamp,
status text,
PRIMARY KEY (order_id, user_id)
) WITH compaction = {
'class': 'UnifiedCompactionStrategy'
};
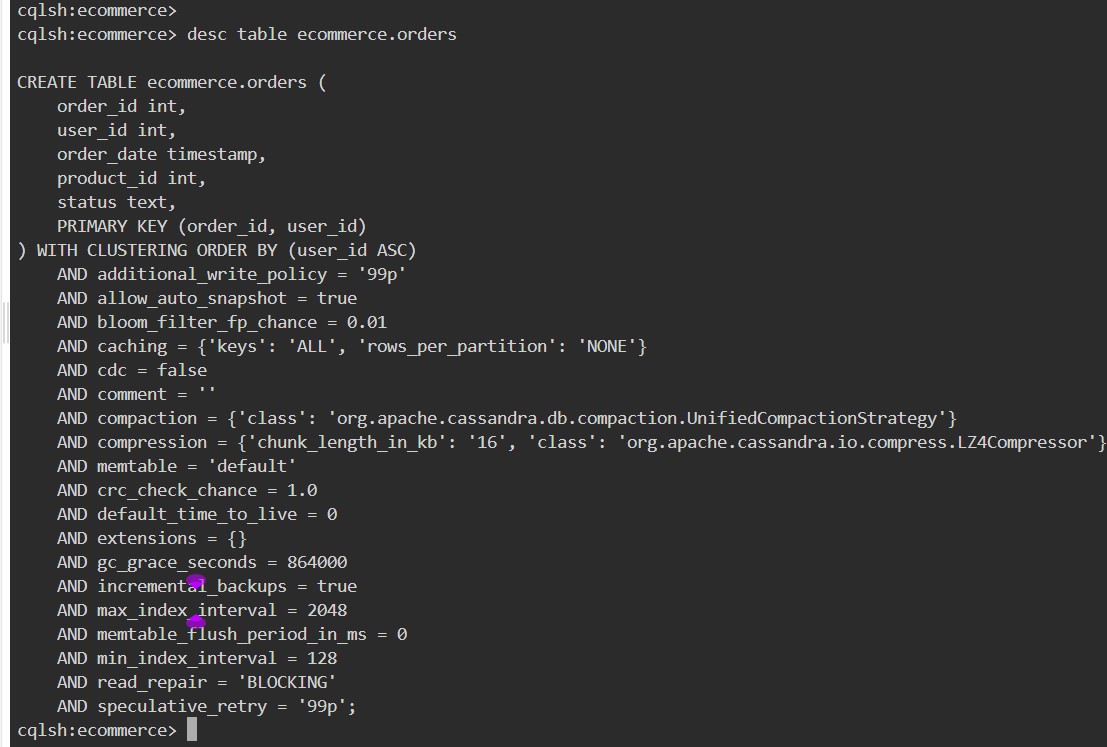
desc table ecommerce.orders



Comments