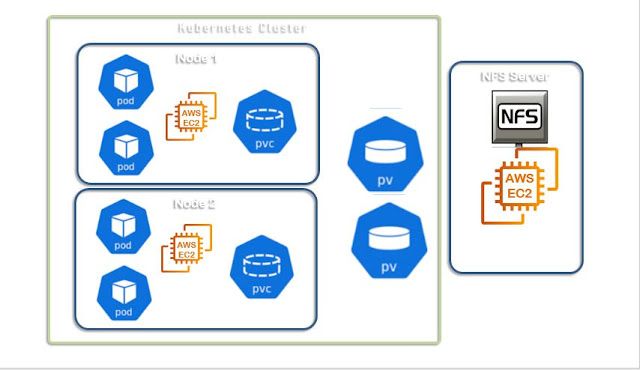
Configuring Fresh Jobs in Jenkins
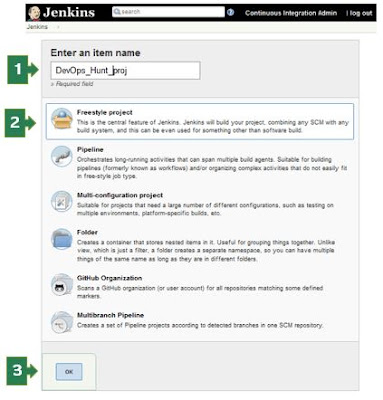
Hello, Dear DevOps Automation enthusiast! This post is intended targeted to those who have just started the journey in the Continuous Integration and Continuous Deployment on the Cloud Platforms or On-premises environments. Pre-requisites Latest Stable version of Jenkins installed Jenkins Master is in running state on your machine/VM/Cloud instance Able to login to the Jenkins Console In the left pane, you can click on 'New Item' or Click on the 'Start Using Jenkins' link. The welcome screen shows a link to create a new job! Jenkins First Job Project creation You need to enter the value for Name for the build project Type of project Freestyle Project Pipeline Multi-configuration Project Folder GitHub Organization Multibranch Pipeline Enter the name of the project, Select the ' Freestyle project ' for the first time and click on the 'OK' button. New page loads with 6 sections/tabs for build project inputs. Job Configuration Sections In ...