Pre-requisites
- Latest Stable version of Jenkins installed
- Jenkins Master is in running state on your machine/VM/Cloud instance
- Able to login to the Jenkins Console
In the left pane, you can click on 'New Item' or Click on the 'Start Using Jenkins' link. The welcome screen shows a link to create a new job!
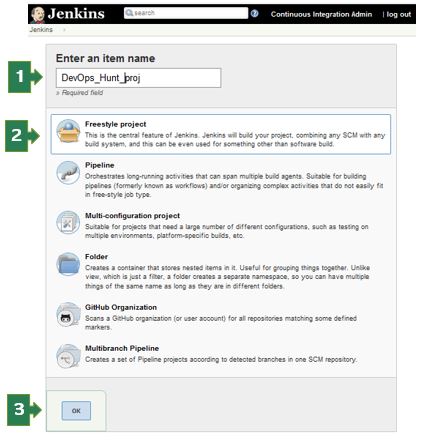 |
| Jenkins First Job Project creation |
You need to enter the value for
Name for the build project
Type of project
- Freestyle Project
- Pipeline
- Multi-configuration Project
- Folder
- GitHub Organization
- Multibranch Pipeline
Enter the name of the project, Select the 'Freestyle project' for the first time and click on the 'OK' button. New page loads with 6 sections/tabs for build project inputs.
Job Configuration Sections
In Jenkins console we have various Job Configuration types

- General - Description of the project, Enable project based security, change date pattern for BUILD_TIMESTAMP, Discard old builds enable will help you for easy migration of Jenkins master.
- Job Notification - End points, You can enable notification mail when someone changed configuration. Rebuild without asking parameters or we can disable the rebuild for a particular job. You can choose the build requires lockable resources, which means other jobs not allowed when this job is in progress. This project is parameterized enabled then you can add different type Parameters such as String Parameter, Choice Parameter, Password Parameter, Node
- Jenkins job configuration allows us to use 5 different choices of 'Source code management' as:
a. Noneb. CVSc. CVS Projectsetd. Gite. Subversion
Build Trigger
- Jenkin's job will be triggered by a 'Build Triggers' section. Here we have Trigger build remotely from scripts,
- Build after other projects are built when there is dependency are in the projects
- Build periodically - This choice asks you on what period you want to execute this job
- Enable Artifactory trigger - when docker image is pushed you want to run a job
- GitHub hook trigger for GITscm polling - requires authentication for webhook accessing GitHub repository
- Poll SCM - for all types of source code repository updates can trigger the job.
Build Environment
Usually, when we run a build, Jenkins uses /tmp/somerandomnumber.sh in Linux machines as the automatically generated script will create workspace in the slave machine.
- Delete workspace before build starts
- Use secret text(s) or file(s)
- Provide configuration files
- send files or execute commands over SSH before the build starts
- send files or execute commands over SSH after the build runs
- Abort the build if it's stuck
- Add timestamps to the Console Output
- Ant/Ivy-Artifactory Integration
- Create a formatted version number
- Farm Repository
- Generic-Artifactory Integration
- Gradle-Artifactory Integration
- Inject environment variables to the build process
- Inject passwords to the build as environment variables
- Inspect build log for published Gradle build scans
- Maven3-Artifactory Integration
- Run Xvnc during build
- Setup Kubernetes CLI (kubectl)
- With Ant
Build
The build section will have an Execute shell with command text box. where you can enter the shell commands. which will become a shell script.
2. Pipeline Project
If you choose the Pipeline Project then it will have the following sections
1. General
2. Job Notifications
3. Build Triggers
4. Advanced Project options
5. Pipeline
General
In the General section, you can see
Enable project-based security
Discard old builds when you check this -> Strategy where you have LogRotation based on - Days to keep builds or Max # of builds to keep
Advance option -
Days to keep artifacts - if not empty default 14, artifacts from builds older than this number of days will be deleted, but the logs, history, reports, etc for the build will be kept
Max # of builds to keep with artifacts - if not empty, only up to this number of builds have their artifacts retained
Do not allow concurrent builds
Do not allow the pipeline to resume if the master restarts
GitHub project
Job Notifications
Notify when Job configuration changes
Pipeline speed/durability override
Preserve stashes from completed builds
Rebuild options: Rebuild Without Asking For Parameters
Disable Rebuilding for this job
Sidebar Links
This project is parameterized selected then you are allowed to use following parameters:
- Node
- String
- Active Choices parameter ->
- Name
- Script option will have choice to enter the Groovy script
- Choice type: Single select, Multi select, Radio button, Checkbox
- Enable Filters
- The filter starts at 1
Build Triggers
- Build after other projects are built
- Build periodically
- Build whenever a SNAPSHOT dependency is built
- Enable Artifactory trigger
- GitHub hook trigger for GITScm polling
- Poll SCM
- Disable this project
- Quiet period
- Trigger builds remotely (e.g., from scripts)
Advanced Project Options
Click on the 'Advanced' button
Pipeline
Definition - Pipeline script
the script, Use Groovy sandbox.
If you are working on the Visual Studio code as editor then you can install the Extention.
Groovy extension

Jenkinsfile Extension









































{kind=link}
{kind=link}
{kind=link}